
This paper proposes Region-Aware Knowledge Distillation (RAKD), a novel method to improve monocular 3D object detection by transferring knowledge from a stronger "expert" model to a lightweight "apprentice" model. Unlike traditional knowledge distillation approaches that rely on LiDAR or multi-camera inputs, RAKD works only with monocular camera data, making it more practical and cost-efficient.
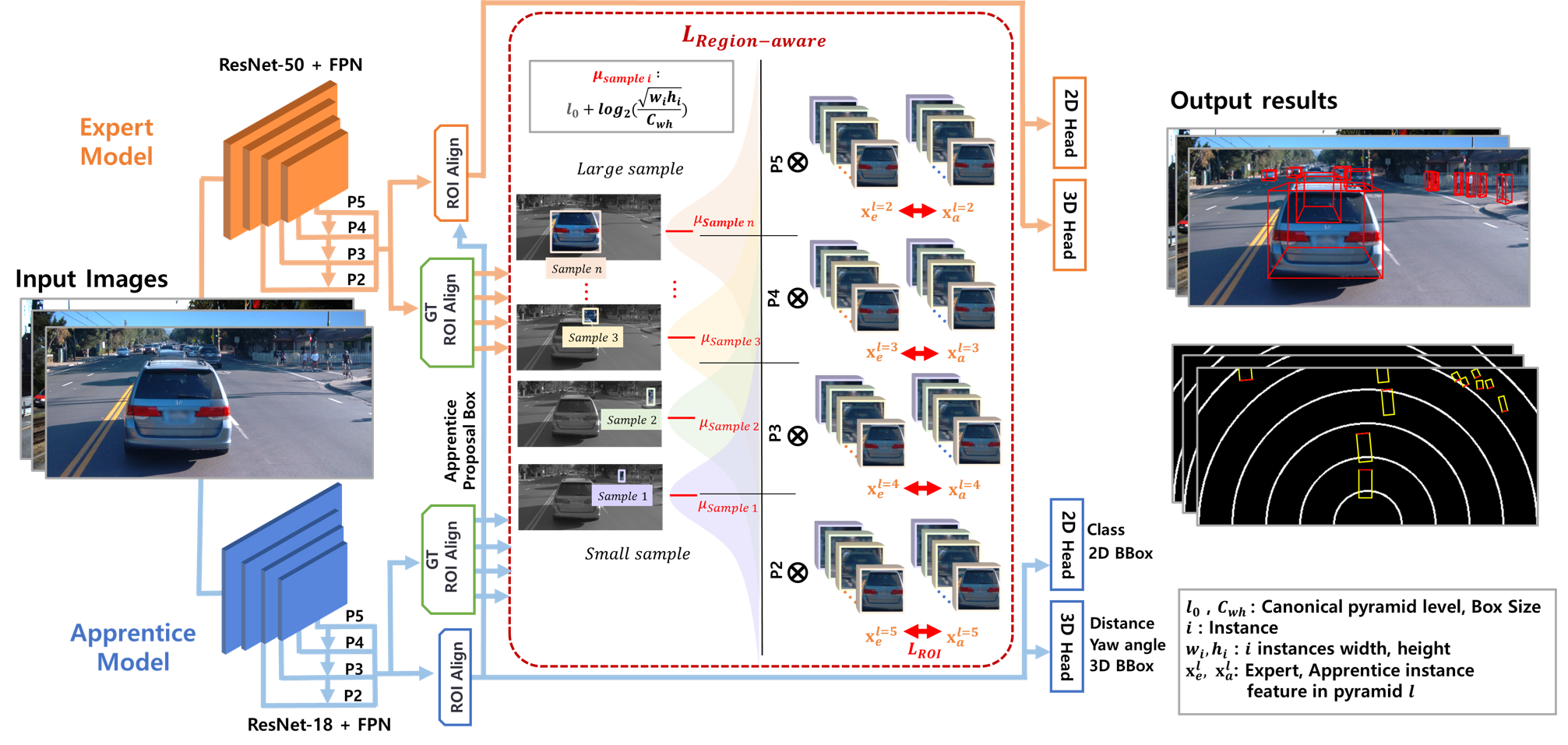
Fig 1. The overall structure of our region-aware knowledge distillation for monocular-based 3D detection.
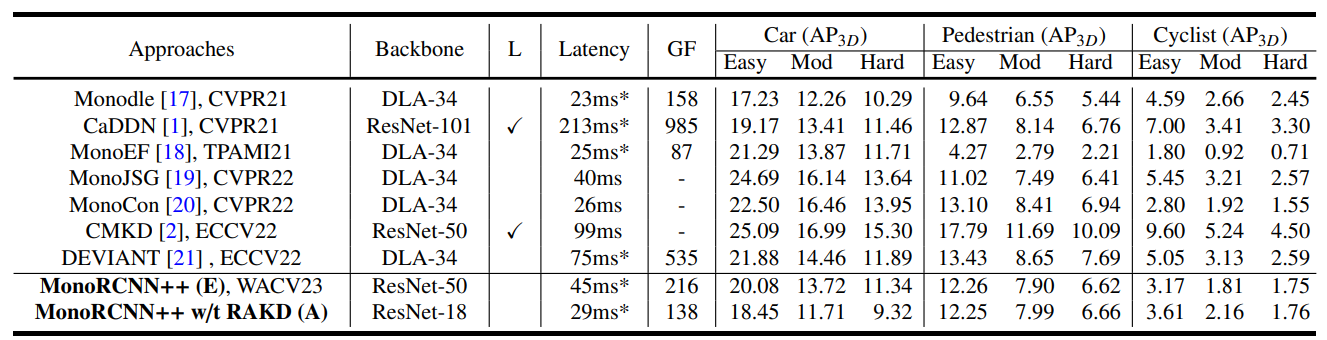
Table 2. Comparisons with state-of-the-art 3D detectors on the KITTI test set. Expert (E) and apprentice (A) detectors applying for RAKD are shown in the
last rows.
Latency measured by ours on the same single NVIDIA TITAN RTX is denoted with ∗. L and GF denote usuage of LiDAR and GFLOPs

Table 3. Comparisons with the recent PKD and SemCKD methods on the KITTI validation set. The best results and second-best scores are highlighted in
bold and underlined (except for expert).
E and A also denote expert and apprentice detectors. All the latency is measured on the same machine.
Avg. represents the score averaged for all classes and occlusion levels.
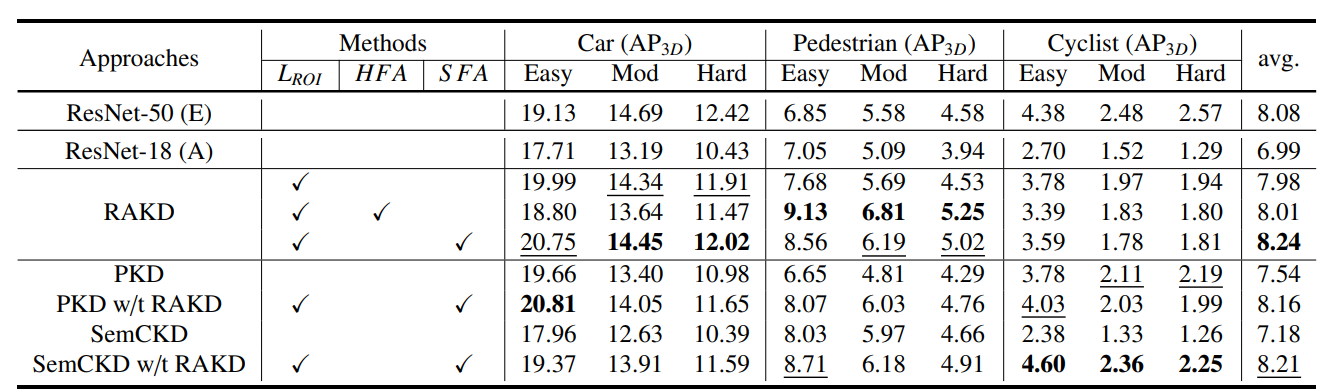
Ablation Study on the KITTI validation set. LRoI represents RoI feature alignment loss, HFA represents Hard feature assignment and SFA
represents Soft feature assignment (LS RoI).
The best results are highlighted in bold, and the second-best results are underlined.